AWS AI-DLC in the APS: Fit Analysis for Large, Regulated Digital Delivery
Methodological Note
This paper analyses AWS's AI-Driven Development Lifecycle (AI-DLC) against a class of APS program, not a specific program under direct observation. The author is a software engineer inside the APS but is a distant observer of the delivery programs described here. Claims about program shape, bottlenecks and delivery mechanics are based on published evidence about SAFe at scale in regulated organisations, general knowledge of APS digital delivery practice and the AI-DLC primary sources listed in the appendix. Where a claim is analysis rather than sourced fact, it is flagged [AJ] (author judgment).
Citation tiers used throughout:
[P]AI-DLC methodology paper (Raja SP, AWS, 2026), page numbers where useful[GH]awslabs/aidlc-workflowsGitHub repository, specific file[AWS]AWS-authored blog or session, with URL and date in the appendix[3P]Third-party source (independent publication, analyst or conference summary)[AJ]Author judgment, not a sourced claim
Limitations
The observations and analysis in this paper should be moderated by the constraints and boundaries detailed below. These limitations are self-disclosed and are grounded in the trial implementation described in Appendix D.
- Greenfield custom software only. Framing and evaluation assume new-build custom code. Commercial off-the-shelf platforms (ServiceNow, Salesforce, Pega, MuleSoft) and BAU maintenance work are out of scope. AI-DLC's Reverse Engineering stage and incremental-change scenarios were not exercised.
- Single practitioner, early adoption. First use of AI-DLC; third use of Superpowers. Judgement improves with repetition and user error is plausible in several places (noted where relevant, e.g. the Level 1 Plan not triggering a simpler path).
- One trial implementation. Empirical evidence comes from a single feature build (Auto Search; see Appendix D), not a portfolio of projects. The project was small-scope and built by one person.
- Inception and Construction only. The Operations phase was not evaluated. At the Operations phase boundary, the trial output "Per the project workflow in CLAUDE.md, the Operations Phase is currently a placeholder" — Operations coverage in the AI-DLC rule set is stub-level at this snapshot
[GH]. - Superpowers comparison is convenience, not equivalence. Superpowers appears in this paper because it was in concurrent use during the trial. It targets individual developers; AI-DLC targets delivery teams. Direct feature comparison is misleading outside that caveat.
- Snapshot in time. April 2026. Both AI-DLC and Superpowers evolve rapidly. Specific gaps called out here may close within one minor release.
- Agent-specific observations. The trial used Claude Code CLI as the AI coding agent. Behaviour may differ with GitHub Copilot, Amazon Q Developer, Cursor or Kiro.
- Practitioner-as-evaluator bias. The author is both user and reviewer of both methodologies. Friction described here may reflect user error as much as methodology weakness.
Generative AI disclosure. This report was drafted and reviewed with the assistance of AI. The trial implementations described in Appendix D were built using AI coding agents. Generative AI can produce inaccurate or incomplete output. The author has reviewed all content and made reasonable efforts to verify claims against primary sources, but readers should apply independent judgment.
Executive Summary
AI-DLC is a well-designed, team-level AI-native coding workflow that is necessary but not sufficient for a digital delivery program of ~200–300 people working on a SAFe Agile Release Train with quarterly major releases, multiple SI vendors and complex regulated government-domain requirements.
What it does well
AI-DLC reimagines the build loop so AI initiates and drives work, humans validate at explicit decision gates and design techniques (e.g. Domain-Driven Design or DDD) are baked into the core rather than left to each team. Its published rule set is concrete, open source and installable in the popular AI coding agents most teams already use. For a single well-scoped feature team working in a new-ish codebase, AI-DLC can compress Inception from weeks to hours and shorten Construction cycles from sprints to days [P].
Where the fit breaks down
The primary constraint on a large APS digital delivery program is structural, not individual: release gating, change management overhead, cross-vendor coordination, regulatory and privacy approvals, APS mandatory compliance and legacy brownfield complexity. AI-DLC's Principle 8 (minimise specialist silos) [P:2] is a deliberate design choice that sits in genuine tension with common mandatory APS specialist roles (e.g. privacy officer, security architect, accessibility lead, data stewards etc). The methodology does not address CI/CD governance, inter-entity release coordination or AI Impact Assessment workflow, because those are explicitly outside its scope.
Conditional framing
- If the bottleneck is team-level code throughput on greenfield or well-contained brownfield work: AI-DLC addresses it directly and the productivity gains are plausible at the levels that AWS claims, subject to the measurement caveats below.
- If the bottleneck is structural (release cadence, CR governance, cross-vendor integration, assurance gates, ministerial-level risk): AI-DLC is necessary but insufficient. Speeding Construction from four weeks to four days does not help if the release window is still quarterly and the CR queue is the gate.
Trial implementation findings
AI-DLC seems a good fit for documentation and compliance focused delivery with strong traceability and audit support. It also dives deeply into requirements and technical design; seeking clarification and suggesting options that match senior level BAs and developers. Two key concerns during trial implementation of Auto Search (see Appendix D for details) are: missing implementation of stated requirements and missing Operations phase. These should be investigated further before further investment of time and energy into AI-DLC.
Productivity claims need care
AWS reports 10–15x productivity gains, 40–60% velocity improvement and 40–60% defect reduction based on 100+ customer experiments [AWS - re:Invent 2025 DVT214; AWS DevOps blog 2026]. Independently measured studies of AI coding assistants report substantially smaller numbers: ThoughtWorks measured a team-level cycle-time improvement of ~8% when Copilot was used on roughly half of tickets, with a broader estimate of 5–15% across organisations; task-specific gains of 30–50% were observed for boilerplate work and 10–40% for business logic [3P - ThoughtWorks 2024]. These numbers are not measuring the same thing. The AWS figure aggregates full-workflow compression (Inception + Construction); the independent figures measure code-authoring or team cycle time. Neither number can be multiplied against total program lead time without a Lean value stream analysis, because coding is typically a small fraction of the total wait-weighted lead time in regulated delivery [3P - Poppendieck 2003; Forsgren, Humble, Kim 2018].
Illustrative math
If individual contributor coding time is 10% of total lead time and AI-DLC delivers a 10x productivity gain on that slice, the program-level lead time reduction is ~9%, not 10x [AJ]. If coding time is 20%, the reduction is ~18%. AI-DLC must be paired with structural interventions on the 80–90% of lead time that is wait, review, gating and coordination to realise meaningful program benefit.
Figure 2 — Lead-time value stream decomposition
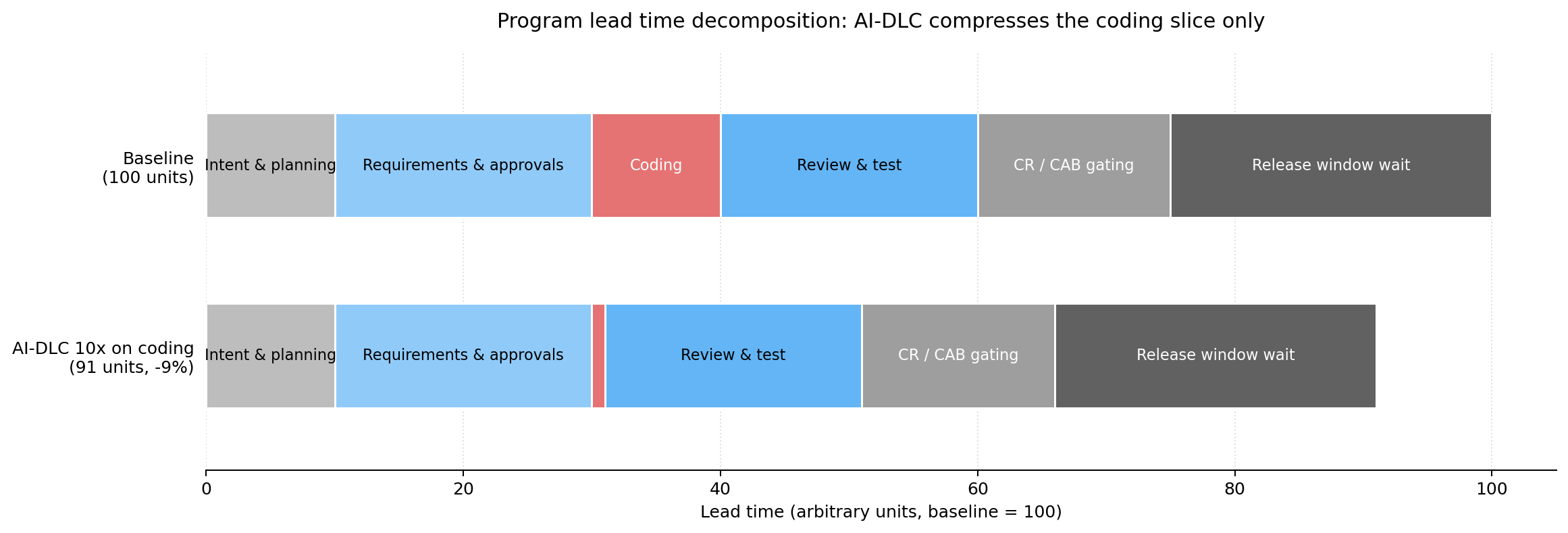
[3P - Poppendieck 2003; Forsgren, Humble, Kim 2018; AJ].Reading the chart: baseline lead time is 100 units; after AI-DLC it is 91 units. The 9-unit reduction is entirely inside the Coding segment. Wait, gating and release-window segments (the majority of lead time in a regulated program) are untouched by AI-DLC itself. If coding is a larger share of the baseline — 20% rather than 10% — the same 10x compression yields ~18% program-level reduction. Either way, the AI-DLC gain is bounded by the size of the coding slice in the current value stream. Measure this slice first [3P - Forsgren, Humble, Kim 2018].
What AI-DLC Is
AI-DLC is an AI-native software development methodology published by AWS in 2026. The methodology paper [P] defines the principles, phases, roles, artefacts and rituals. The awslabs/aidlc-workflows GitHub repository [GH] publishes the concrete rule files that make the methodology executable inside an AI coding agent.
Ten principles
- Reimagine rather than retrofit
- Reverse the conversation direction (AI initiates, human validates)
- Integrate design techniques into the core (first flavour is Domain-Driven Design)
- Align with current AI capability (AI-Driven, not fully autonomous)
- Cater to building complex systems (not low-code use cases)
- Retain what enhances human symbiosis (user stories, risk register)
- Facilitate transition through familiarity (Sprints rebranded as Bolts)
- Streamline responsibilities for efficiency (minimise specialist silos)
- Minimise stages, maximise flow (human validation as "loss function")
- No hard-wired opinionated SDLC workflows (AI proposes a Level 1 Plan per intent)
Figure 1 — AI-DLC phases, rituals and human approval gates
%%{init: {'theme': 'neutral', 'themeVariables': {'edgeLabelBackground': '#ffffff'}}}%%
flowchart TB
PO([Product Owner articulates Intent])
PO --> L1[AI generates Level 1 Plan]
L1 --> G0{{Human validates and approves Plan}}
G0 --> Inception
subgraph Inception[INCEPTION PHASE]
In1[AI drafts user stories, NFRs, risks, PRFAQ]
In1 --> In2[Team validates, refines, challenges]
In2 --> In3[Units defined plus suggested Bolt plan]
end
Inception --> G1{{Approve Units and Bolt plan}}
G1 --> Construction
subgraph Construction[CONSTRUCTION PHASE]
Co1[Domain Design - DDD modelling]
Co1 --> Co2[Logical Design plus ADRs, NFRs, cloud patterns]
Co2 --> Co3[Code plus Unit Tests]
Co3 --> Co4[Functional, security, performance tests]
Co4 --> Co5[Deployment Unit ready]
Co5 -. next Bolt or next Unit .-> Co1
end
Construction --> G2{{Approve deployment}}
G2 --> Operations
subgraph Operations[OPERATIONS PHASE]
Op1[Deploy to staging or production]
Op1 --> Op2[AI analyses telemetry, detects anomalies]
Op2 --> Op3[AI proposes runbook actions]
Op3 --> Op4[Human approves, monitors outcome]
end
classDef gate fill:#fff4d4,stroke:#b58900,color:#333
class G0,G1,G2 gate
Yellow diamonds mark the human approval gates that AI-DLC treats as a "loss function" that catches and prunes errors early before they propagate downstream [P:3]. Inception uses the Mob Elaboration ritual; Construction uses Mob Construction and Mob Testing rituals, iterating through Bolts of hours-to-days; Operations runs AI-driven telemetry analysis with human approval on proposed actions.
Trial implementation note: The author's Auto Search trial accumulated 15 explicit review gates with three Units remaining before the author elected to autocomplete the rest to avoid review fatigue. [AJ]
Three phases
- Inception Phase. Captures Intents, runs Mob Elaboration to decompose them into Units and User Stories, produces PRFAQ, NFRs, Risks and Measurement Criteria.
- Construction Phase. Iteratively turns Units into Deployment Units through Domain Design → Logical Design → Code and Unit Tests → Build and Test. AWS services are selected against well-architected principles.
- Operations Phase. AI analyses telemetry, proposes runbook actions, humans validate and approve.
Key artefacts: Intent, Unit (equivalent to Epic/Subdomain), Bolt (rapid iteration, equivalent to Sprint), Domain Design, Logical Design, Deployment Unit [P:3-4].
Adaptive depth
Inspection of the rule files confirms two mechanisms [GH: core-workflow.md; inception/workflow-planning.md]:
- AI generates a Level 1 Plan that recommends which optional stages to execute or skip, with rationale. Humans approve or override before any stage runs.
- Some stages are explicitly conditional in the rule files (Reverse Engineering is brownfield-only; User Stories and Application Design are conditional on complexity and user-facing impact).
Mandatory stages (Workspace Detection, Requirements Analysis, Workflow Planning, Code Generation, Build and Test) always run. Requirements Analysis always executes but varies between Minimal, Standard and Comprehensive depth.
Figure 3 — Adaptive workflow and Level 1 Plan mechanism
%%{init: {'theme': 'neutral'}}%%
flowchart TB
I([Intent]) --> L1[AI: generate Level 1 Plan]
L1 --> G{{Human: approve or override plan}}
G -->|brownfield detected| RE[Reverse Engineering]
G -->|always| WD[Workspace Detection]
RE --> WD
WD --> RA[Requirements Analysis - Minimal or Standard or Comprehensive depth]
RA --> WP[Workflow Planning]
WP -->|user-facing and complex| US[User Stories]
WP -->|if warranted by plan| AD[Application Design]
WP -->|always| CG[Code Generation]
US --> CG
AD --> CG
CG --> BT[Build and Test]
BT --> DU([Deployment Unit])
EXT[Extensions - opt-in, hard constraints on non-compliance]
EXT -.->|APS hooks go here| RA
EXT -.-> BT
classDef mandatory fill:#dbeafe,stroke:#3b82f6,color:#1e3a5f
classDef cond fill:#fef3c7,stroke:#d97706,color:#78350f
classDef gate fill:#fff4d4,stroke:#b58900,color:#333
classDef ext fill:#dcfce7,stroke:#16a34a,color:#14532d
class WD,RA,WP,CG,BT mandatory
class RE,US,AD cond
class G gate
class EXT ext
The extension mechanism is where APS-specific gates (PIA, AIIA, ISM, accessibility) attach without modifying the core workflow [GH: core-workflow.md].
Extensions
The rule files ship with two extensions (security baseline, property-based testing). Extensions follow an opt-in pattern at Requirements Analysis via *.opt-in.md files [GH: core-workflow.md]. Enabled extensions are hard constraints and block stage completion on non-compliance. This is the correct extension point for APS-specific additions (Privacy Impact Assessment, AI Impact Assessment, DTA Digital Service Standard 2.0 checklist, accessibility compliance).
Installation paths
AI-DLC rule files can be placed in .aidlc-rule-details/ for GitHub Copilot workspace rules, Cursor, Cline, Claude Code CLI or OpenAI Codex; in .amazonq/aws-aidlc-rule-details/ for Amazon Q Developer; or in .kiro/aws-aidlc-rule-details/ for Kiro IDE [GH: core-workflow.md].
GovAI Chat is not a compatible installation target. GovAI Chat is a web chat interface coming to universal APS availability mid-2026. It does not execute workspace rule files against a working tree. GovAI Chat is useful for Mob Elaboration sessions (facilitated conversation, artefact generation into documents); it is not the primary AI coding agent for AI-DLC.
Pros and Cons
| Dimension | Strength | Limitation |
|---|---|---|
| Design integrity | Built from first principles around AI capability, not retrofitted onto Scrum. Design techniques (DDD) baked into the core [P:2]. | Only one flavour (DDD) published; BDD and TDD flavours referenced but not yet defined [P:2]. |
| Openness | Rule files are open source under AWS Labs [GH]. Installable in multiple agents. | Rules cover the "happy path" well; real programs need heavy extension work for regulated contexts. |
| Workflow compression | Mob Elaboration compresses weeks of sequential work into hours [P:4]. Construction cycles move from sprints to days. | Compression benefits are team-local. Structural gates (CR, release windows, inter-entity coordination) are unchanged. |
| Artefact traceability | All artefacts are persisted and linked; forward and backward traceability is explicit [P:5]. | Traceability is to AI-DLC artefacts, not to APS enterprise tooling (Jira, ADO, TRIM/CM, BRS/SRS templates). Bridging is the program's job. |
| Human oversight model | Explicit approval gates at every critical decision; oversight framed as a "loss function" [P:3] that catches errors before they propagate. | Gate density is high enough that total cycle time still depends heavily on reviewer availability. For APS, that reviewer bottleneck is real. |
| Role design | Principle 8 minimises specialist silos and empowers T-shaped developers. Works in teams that are already cross-functional. | Creates genuine tension with APS mandatory specialist roles (see gap analysis). |
| Brownfield coverage | Reverse Engineering stage produces semantic models of existing code before changes are attempted [P:5-6]. | Real APS brownfields include legacy COTS, third-party integrations and legislative-reference data stores that do not reduce cleanly to DDD aggregates [AJ]. |
| Productivity ceiling | Genuinely high for coding-bound teams. AWS cites 10–15x improvements plus 40–60% velocity and 40–60% defect reduction from 100+ customer experiments [AWS - re:Invent 2025 DVT214]. | Independent measurement from ThoughtWorks sits at ~8% team cycle-time improvement, 5–15% across organisations, and 30–50% on boilerplate tasks specifically [3P - ThoughtWorks 2024]. The two sets of numbers measure different things. |
| Records and audit | Every interaction and decision is logged to aidlc-docs/audit.md with ISO timestamps and raw user responses [GH]. | Not aligned with APS records management (National Archives Act obligations, agency record schedules). Bridging required. |
| Vendor lock-in risk | Rule files are portable across AI agents. Methodology itself is agent-agnostic. | Construction phase explicitly maps to AWS services [P:3-5]. Teams delivering on Azure (substantial in APS) will need to rewrite Logical Design rules. |
Gap Analysis vs APS Mandatory Requirements
Mapping AI-DLC against the APS digital delivery mandatory layer. Ratings: Covered / Partial / Gap.
| APS Requirement | Coverage | Analysis |
|---|---|---|
| DTA Digital Service Standard 2.0 (14 criteria) | Partial | Criteria 1 (user needs) and 2 (solve a whole problem) align with Inception and PRFAQ. Criteria 4, 6, 7, and 12 have no explicit coverage and need to be layered in as extensions. [AJ] |
| APS AI Plan 2025 | Gap | AI-DLC assumes the organisation has already decided which AI tools to use and that usage is approved. APS AI Plan expects governance, risk classification and assurance processes around AI adoption itself. |
| DTA AI Policy v2.0 | Gap | Requires AI Impact Assessment for specified categories of AI use. AI-DLC has no hook for AIIA artefacts, thresholds or sign-offs. Must be added as an opt-in extension. |
| AI Impact Assessment workflow | Gap | Separate workflow that must gate Inception and, for some system classes, Deployment. AI-DLC's Level 1 Plan needs an AIIA stage wired in before Requirements Analysis for in-scope systems. |
| Privacy Impact Assessment (Privacy Act 1988, APPs) | Gap | Not referenced in AI-DLC. PIA is mandatory for systems handling personal information above threshold. Must be added as an opt-in extension with explicit approval gate. |
| Information Security Manual (ISM) controls | Partial | Security extension in the published rule set addresses baseline software security [GH]. Does not map to ISM control families or Essential Eight maturity levels. Extension rewrite required. |
| Protective Security Policy Framework (PSPF) | Gap | Data classification, personnel clearance, physical security not addressed. These constrain where AI coding agents can be used (OFFICIAL: Sensitive data cannot be sent to non-sovereign endpoints). AI-DLC is silent on classification handling. |
| WCAG 2.2 AA (DDA 1992 exposure) | Gap | No accessibility testing in the construction phase. Must be added as an extension with automated and manual gates. |
| Indigenous Data Sovereignty (CARE principles, where applicable) | Gap | Not addressed. For systems holding Indigenous data, this is a mandatory design consideration. |
| Records management (National Archives Act 1983) | Partial | AI-DLC logs decisions to audit.md [GH]. Not a registered record. Program needs a bridge from AI-DLC artefacts into the agency's records management system. |
| Procurement (CPRs, APS Panel arrangements) | Out of scope | Not an AI-DLC concern; flagged because AI tool selection and vendor engagement sit upstream of AI-DLC adoption. |
| Gateway Reviews, Investment Management Standard | Out of scope | Program-level assurance layer. AI-DLC can feed evidence into Gate reviews but does not replace them. |
| Information and Performance Measurement Framework (IPMF) | Partial | AI-DLC produces Measurement Criteria at Inception [P:4]. Not aligned with IPMF's outcome categories out of the box. |
| SAFe-mandated artefacts (PI Objectives, Features, Capabilities) | Gap | AI-DLC's Intent / Unit / Bolt hierarchy does not map cleanly to Epic / Feature / Story / Task in SAFe. See Appendix A. Program must maintain the mapping manually until a flavour is built. |
Framing note [AJ]: Framing APS gaps as things to "add as an extension" is partially correct and partially misleading. Rulesets can extend what the AI does inside a coding session. They cannot substitute for organisational capability, infrastructure maturity, regulatory compliance workflows or inter-entity relationships. The assessment is not that AI-DLC is deficient — it is that AI-DLC is one layer in a multi-layer compliance stack and was not designed to address the other layers.
Figure 4 — APS compliance overlay
%%{init: {'theme': 'neutral'}}%%
flowchart TB
subgraph APS[APS MANDATORY LAYER]
subgraph AIDLC[AI-DLC NATIVE SCOPE]
IN[Inception] --> CO[Construction] --> OP[Operations]
end
PIA[PIA - Privacy Act 1988 / APPs]
AIIA[AIIA - DTA AI Policy v2.0]
DSS[DSS 2.0 - 14 criteria]
PSPF[PSPF - data classification]
ISM[ISM / Essential Eight - ACSC]
ACC[WCAG 2.2 AA - DDA 1992]
REC[Records - National Archives Act]
end
PIA -->|gate before| IN
AIIA -->|gate before| IN
DSS -->|criteria 1-2 align| IN
PSPF -->|classification scope| IN
PSPF -->|tool approval| CO
ISM -->|security controls| CO
ACC -->|accessibility testing| CO
REC -->|artefact bridge| CO
classDef aps fill:#fef3c7,stroke:#d97706,color:#78350f
classDef aidlc fill:#dbeafe,stroke:#3b82f6,color:#1e3a5f
class PIA,AIIA,DSS,PSPF,ISM,ACC,REC aps
class IN,CO,OP aidlc
Competitive Landscape Summary
Adjacent offerings from major consultancies and vendors. The distinction that matters most is whether the offering is a methodology (reusable process), a platform (tooling) or a service (paid engagement).
- ThoughtWorks AI/works
[3P]. Platform plus methodology. Six capabilities: Reverse Engineering, Dynamic Spec Development, Spec to Code, Developer Experience, Control Plane, Runtime Ops. "3-3-3" framework: 3 days to concept, 3 weeks to prototype, 3 months to MVP. Independently measured: ~8% team cycle-time improvement; 5–15% across organisations; 30–50% on boilerplate; 10–40% on business logic. Stronger emphasis on legacy modernisation than AI-DLC. - Consultancy offerings (McKinsey / QuantumBlack, PwC, Deloitte and similar). Service-shaped rather than methodology-shaped. Emphasis on value-case framing, executive communication and risk/assurance wrap around AI-assisted delivery.
[AJ] - GitHub Copilot Workspace + workspace rules. Tooling, not methodology. AI-DLC rule files install directly into this context.
- Amazon Q Developer. Vendor-aligned to AI-DLC
[GH]. Natural fit if the program is AWS-heavy. - Claude Code CLI, Cursor, Cline. Coding agents with rule-file support. AI-DLC portable to all three
[GH]. - Kiro IDE. AWS-aligned IDE with native AI-DLC support
[GH].
For a program that wants portable methodology over product and engagements, AI-DLC is a strong starting point. The principal qualifications are the APS mandatory layer gaps identified above and the trial implementation findings (interaction overhead, instruction adherence gaps, and model fine-tuning outcome) detailed in Appendix D.
Daily Workflow Overview
A typical AI-DLC flow for a new business capability, with program-level context woven in [P]; [GH].
Week 0 — Intent and Level 1 Plan
- Product Owner articulates an Intent, e.g. "Add a provider eligibility check for a new programme stream."
- AI (the team's coding agent running AI-DLC rules) generates a Level 1 Plan recommending which stages to execute
[GH: core-workflow.md]. The team reviews the Plan, approves or amends and agrees the scope of this increment (one Unit or multiple). - The Plan is written to
aidlc-docs/inception/plans/execution-plan.mdand locked behind an explicit approval[GH: workflow-planning.md].
Week 0–1 — Mob Elaboration (Inception)
- Whole-team session in one room (or virtual equivalent) with a shared screen. Product Owner, developers, QA, UX, tech lead. Facilitator drives
[P:3-4]. - AI asks clarifying questions, generates candidate user stories, NFRs, risks and a PRFAQ. The team challenges, adjusts and validates.
- Output: one or more Units, each with user stories, acceptance criteria, NFRs, risk register entries, measurement criteria and a suggested Bolt plan.
- Mob Elaboration replaces what would otherwise be days of elicitation workshops + BA writing + review loops. In a regulated APS context, it does not replace the AI Impact Assessment, Privacy Impact Assessment or accessibility review — these must be wired in as extension gates before Requirements Analysis completes.
Weeks 1–N — Mob Construction (Construction)
Per Unit, the team (often a small pair, sometimes a full mob) works through the Construction sequence with AI driving and humans validating:
- Domain Design. AI proposes aggregates, entities, value objects, domain events, repositories, factories
[P:3]. Developer validates against real-world scenarios. - Logical Design. AI extends Domain Design with architectural patterns (CQRS, event-driven, circuit breakers) and candidate services (Lambda, Fargate, DynamoDB, etc.)
[P:3-5]. Developer approves or overrides. - Architecture Decision Records. AI writes ADRs for each significant decision. Developer reviews and approves.
- Code and Unit Tests. AI generates both from Logical Design. Developer inspects, runs, adjusts.
- Build and Test. AI executes functional, security and performance tests. On failures, AI proposes fixes; developer approves re-runs
[P:6-7].
Each cycle is a Bolt: hours to days, not weeks. Multiple Bolts per Unit, in parallel where Units are loosely coupled. Program-level integration with other teams on the ART still happens at PI Planning, System Demo and Integration Events — the Bolt does not replace these.
Continuous — Operations
AI analyses production telemetry (metrics, logs, traces), detects anomalies, predicts SLA breaches, recommends runbook actions [P:5-7]. Developer on-call validates, approves, monitors outcome. This is the weakest-specified phase in the methodology. In practice, most APS programs have mature observability platforms already running. AI-DLC Operations complements these; it does not replace them.
Role-by-Role Breakdown
How existing roles change. AI-DLC's Principle 8 deliberately reduces specialist silos [P:2]. In an APS context this is not followed in full; roles below are the practical reconciliation.
| Role | What changes | What does not change |
|---|---|---|
| Product Owner | Spends less time writing detailed requirements, more time validating AI-generated artefacts and making trade-off decisions. Runs Mob Elaboration in partnership with the tech lead. | Stakeholder management, priority setting, business outcomes ownership, partner agency relationships. |
| Business Analyst | Role compresses inside Mob Elaboration. Primary value shifts to preparing the Intent, supplying domain knowledge during elaboration and translating between AI-DLC artefacts and agency-mandated artefacts. | Liaison with regulated stakeholders. Writing of statutorily required documentation (PIA, AIIA narrative) stays with BAs or specialist officers. |
| Developer | Works primarily as a validator of AI-generated Domain Design, Logical Design, Code and Tests. Makes architectural decisions; produces less hand-written code [P:3]. | Code ownership, on-call responsibilities, production quality accountability. |
| Tech Lead / Solutions Architect | Runs Mob Construction rituals. Owns Logical Design approval. Heavier ADR review load. | Cross-team interface management, architectural governance at ART level. |
| QA / Test Engineer | Validates AI-generated test scenarios and cases, not just test execution. Closer involvement during Domain and Logical Design (shift-left). | Exploratory testing, user acceptance testing facilitation, regression strategy. |
| DevOps / Platform Engineer | AI-DLC proposes infrastructure (CloudFormation, CDK, Terraform). Role shifts to platform policy, guardrails and golden-path templates that AI-DLC generation conforms to. | CI/CD pipeline ownership, environment management, release engineering. |
| Security / Privacy / Accessibility Specialists | In AI-DLC's native form, these roles are absorbed into the developer. In an APS program, they are retained as distinct approvers for their statutory and policy responsibilities. The APS extension pack adds their gates explicitly. [AJ] | Statutory sign-off, attendance at change advisory boards, liaison with independent assurance. |
| Scrum Master / RTE | Sprint ceremonies partially replaced by Bolt rhythm. PI-level ceremonies unchanged. Coaching load increases during transition. | PI Planning facilitation, Scrum of Scrums, impediment management. |
Records Generated
What the team produces, where it lives and how it integrates with agency records. AI-DLC native records (all live under aidlc-docs/ in each repository) [GH: various rule files]:
aidlc-docs/audit.md— append-only log of every AI prompt, user response (raw), approval and decision, ISO-timestamped.aidlc-docs/aidlc-state.md— current stage, execution plan, extension configuration, stage progress checklist.aidlc-docs/inception/plans/execution-plan.md— the approved Level 1 Plan for the increment.aidlc-docs/inception/requirements/requirements.md— functional and non-functional requirements.aidlc-docs/inception/requirements/requirement-verification-questions.md— clarifying questions and answers.aidlc-docs/story-artifacts/*.md— per-Unit user stories and acceptance criteria.aidlc-docs/design-artifacts/— Domain Design, Logical Design, ADRs per Unit.aidlc-docs/construction/plans/*-code-generation-plan.md— approved code generation plans per Unit.aidlc-docs/inception/reverse-engineering/(brownfield only) — architecture, component inventory, technology stack, dependencies, business overview, interaction diagrams.
Bridging to agency records (APS extension pack adds these) [AJ]:
- PIA artefact linked from
aidlc-docs/inception/compliance/and logged in agency records system. - AIIA artefact linked and logged against the system register required under DTA AI Policy v2.0.
- Accessibility test reports (automated + manual) linked.
- Security assessment (ISM mapped) linked.
- BRS/SRS abridged artefacts where agency gate processes still require them. Treat these as derived from AI-DLC artefacts, not separately maintained.
- Records of significant architectural decisions logged under agency architecture governance in addition to ADRs in-repo.
Integration with SAFe ART and CR Process
Key framing [AJ]: SAFe and AI-DLC overlap in their objective (flow of value through a regulated organisation) but disagree on cadence and role shape. The program must choose a reconciliation and hold it.
- PI Planning. Keep it. AI-DLC does not address cross-team planning at program level. Intents captured at or feeding PI Planning become inputs to Mob Elaboration sessions. Recommended rhythm: Mob Elaborations happen during or immediately after PI Planning for the top-priority Intents, such that Units are ready before Bolts start.
- Feature / Story decomposition. Replace SAFe Feature writing with AI-DLC Mob Elaboration for the portion of Features owned by AI-DLC teams. Features become equivalent to AI-DLC Units (approximately — see Appendix A). Maintain a Feature → Unit mapping in ART-level tooling so RTE-level reporting continues to work.
- Iterations / Sprints. Replace with Bolts for AI-DLC teams. The SAFe 2-week iteration becomes a container for multiple Bolts. Team Demo can move to System Demo cadence only.
- System Demos and Integration Events. Keep. These are cross-team and have no AI-DLC equivalent.
- Change Request process. Integration with change management is the most uncertain aspect. For each Deployment Unit, the program's change process still applies. What does change is the quality of CR evidence — AI-DLC artefacts (ADRs, test reports, risk register, audit log) give change advisory boards richer input than typical CR packs. Recommendation: agree a CR evidence template that maps to AI-DLC artefacts so reviewers read the template, not the entire
aidlc-docs/tree.[AJ] - Release train cadence. Quarterly major releases are structural. AI-DLC does not touch this unless the program decides to shorten the release window. That decision is independent of AI-DLC adoption.
Tool Compatibility
Compatible coding agents
- GitHub Copilot + workspace rules. Rules in
.aidlc-rule-details/. Widely available across APS under existing Microsoft enterprise agreements. - Amazon Q Developer. Rules in
.amazonq/aws-aidlc-rule-details/. Native vendor path. - Claude Code CLI. Rules in
.aidlc-rule-details/. Requires direct API access (internal endpoint via GovAI Model Brokerage or, for developers with approved access, the Anthropic API). - Cursor, Cline. Rules in
.aidlc-rule-details/. Case-by-case agency approval. - Kiro IDE. Rules in
.kiro/aws-aidlc-rule-details/. AWS-aligned IDE. - OpenAI Codex. Rules in
.aidlc-rule-details/.
Not a compatible installation target: GovAI Chat. A web chat interface, scheduled for universal APS availability mid-2026. It does not execute workspace rules against a working directory. GovAI Chat is still useful for AI-DLC, specifically for Mob Elaboration sessions where the team needs a shared AI conversation on a screen with no code execution. It is not the primary AI coding agent.
Data Classification
AI-DLC is silent on classification. For OFFICIAL: Sensitive or higher, use only model endpoints approved for that classification. This is a program-level control, not an AI-DLC-level control.
Appendix A — Glossary and SAFe Mapping
Approximate equivalences. Not exact because AI-DLC and SAFe structure work differently.
| AI-DLC Term | Definition | SAFe / APS Equivalent (approx.) |
|---|---|---|
Intent [P:3] | High-level statement of purpose: business goal, feature or technical outcome. Entry point to the workflow. | SAFe Epic (business or enabler). Program-level driver. |
Unit [P:4] | Cohesive, self-contained work element derived from an Intent, delivering measurable value. Loosely coupled with other Units. | SAFe Feature (most closely). Sometimes Capability for larger Units. DDD Subdomain. |
User Story [P:4] | Articulates functional scope within a Unit, includes acceptance criteria. Retained unchanged from Scrum. | SAFe Story. Direct equivalent. |
Bolt [P:3-4] | Smallest iteration: hours to days. Rapid implementation of a Unit or tasks within a Unit. | SAFe Iteration (partial). Closer to a "slice" within an Iteration. |
PRFAQ [P:4] | Press-release-plus-FAQ artefact from Inception, summarising business intent, functionality, benefits. | Feature intent narrative. Business case summary. |
Mob Elaboration [P:3-4] | Collaborative Inception ritual: AI proposes, team validates, in one room with shared screen. | Feature workshop. Program Backlog Refinement, intensified. |
Mob Construction [P:5] | Collaborative Construction ritual. Teams collocated during Domain Design and integration steps. | Mob programming + integration event. |
Domain Design [P:3] | DDD-shaped core business logic model. Aggregates, entities, value objects, domain events, repositories, factories. | SAFe Solution Intent (partial). Enterprise domain model. |
Logical Design [P:3] | Extension of Domain Design applying NFRs and architectural patterns. Cloud-service-level. | Solution Architecture. High-Level Design. |
ADR [P:3] | Captured architectural decision with context and consequences. | ADR (same term in SAFe and most APS programs). |
Deployment Unit [P:3-4] | Packaged executable code + configurations + infrastructure, tested for functional, security, NFR and operational risk. | Release artefact. Deployable increment. |
Level 1 Plan [GH] | AI-generated top-level plan recommending which stages run; human-approved. | PI-level scope plan for the increment. |
Loss Function (human oversight) [P:3] | Metaphor for human validation catching and pruning errors early. | Gate / review / approval checkpoint. |
Extension [GH] | Opt-in rule module enforceable as a hard constraint during the workflow. | Compliance pack. Standards overlay. |
Figure 5 — AI-DLC ↔ SAFe hierarchy
%%{init: {'theme': 'neutral'}}%%
flowchart LR
subgraph SAFe[SAFe ART]
E[Epic] --> F[Feature or Capability]
F --> IT[Iteration or Sprint]
IT --> S[Story]
S --> T[Task]
end
subgraph AIDLC[AI-DLC]
IN[Intent] --> U[Unit]
U --> B[Bolt]
B --> US[User Story]
end
E -. approx .-> IN
F -. approx .-> U
IT -. approx, Bolt is faster .-> B
S -. direct equivalent .-> US
classDef safe fill:#dbeafe,stroke:#3b82f6,color:#1e3a5f
classDef aidlc fill:#fef3c7,stroke:#d97706,color:#78350f
class E,F,IT,S,T safe
class IN,U,B,US aidlc
Key tensions: a Bolt (hours to days) is much faster than a SAFe Iteration (2 weeks), so multiple Bolts fit inside one Iteration. A Unit maps closest to a Feature but can span Feature-to-Capability scale depending on scope. Programs must maintain an explicit Feature → Unit mapping in ART tooling for RTE-level reporting to continue working.
Appendix B — Extended Gap Analysis Table (APS Mandatory Layer)
"Blocking level" = High/Blocking means the gap must be closed before production use; Medium means must be closed before scaled use; Low means can be closed incrementally.
| # | APS Requirement | Source | AI-DLC Native Coverage | Extension Effort | Blocking Level |
|---|---|---|---|---|---|
| 1 | DSS 2.0 — User needs | DTA | Partial | Low | Medium |
| 2 | DSS 2.0 — Solve a whole problem | DTA | Partial | Low | Medium |
| 3 | DSS 2.0 — Make it accessible (WCAG 2.2 AA) | DTA, DDA 1992 | None | Medium (automated + manual gates) | High |
| 4 | DSS 2.0 — Multidisciplinary team | DTA | Conflict | Medium (extension pack retains roles) | Medium |
| 5 | DSS 2.0 — Make source code open | DTA | None | Low (policy decision + release automation) | Low |
| 6 | APS AI Plan 2025 alignment | DoF / GovAI | None | Medium (governance hooks, system register) | High |
| 7 | DTA AI Policy v2.0 | DTA | None | Medium (AIIA extension, threshold logic) | High |
| 8 | AI Impact Assessment workflow | DTA | None | Medium (gate before Requirements Analysis) | Blocking |
| 9 | Privacy Impact Assessment | Privacy Act 1988, APPs | None | Medium (PIA extension + gate) | Blocking |
| 10 | Information Security Manual mapping | ACSC | Partial | Medium (ISM control mapping, E8 level) | Blocking |
| 11 | Protective Security Policy Framework | AGD | None | Medium (classification handling, personnel, physical) | Blocking |
| 12 | WCAG 2.2 AA testing | W3C, DDA 1992 | None | Low-Medium | High |
| 13 | Indigenous Data Sovereignty (CARE principles) | AIATSIS et al. | None | Medium (for in-scope systems) | Blocking (in scope) |
| 14 | National Archives Act 1983 records | NAA | Partial | Low-Medium (records bridge) | High |
| 15 | CPRs, Panel arrangements | DoF | Out of scope | n/a | n/a |
| 16 | Gateway Reviews, IMS | DoF | Out of scope | n/a (feeds evidence) | n/a |
| 17 | IPMF outcome measurement | DoF | Partial | Low | Low |
| 18 | SAFe PI / Feature / Story alignment | Scaled Agile | Partial via mapping | Low (mapping conventions) | Medium |
Appendix C — Full Source List
Primary (AI-DLC methodology)
[P]Raja SP. AI-Driven Development Lifecycle (AI-DLC) Method Definition. Amazon Web Services, 2026. 10-page methodology paper.[GH]awslabs/aidlc-workflowsGitHub repository. https://github.com/awslabs/aidlc-workflows.[GH: core-workflow.md]aidlc-rules/aws-aidlc-rules/core-workflow.md. Defines mandatory vs conditional stages, adaptive depth, extension loading.[GH: inception/requirements-analysis.md]Adaptive requirements analysis rule file. Confirms Minimal/Standard/Comprehensive depth selection.[GH: inception/workflow-planning.md]Level 1 Plan generation with human approval gate.[GH: construction/code-generation.md]Code generation stage with per-unit planning and approval.[GH: extensions/]Security-baseline and property-based-testing extensions; opt-in pattern via*.opt-in.mdfiles.
Vendor and adjacent
[AWS]Raja SP and Mishra A. AI-Driven Development Life Cycle: Reimagining Software Engineering. AWS DevOps and Developer Productivity Blog, 2026. Link.[AWS]Open-Sourcing Adaptive Workflows for AI-Driven Development Life Cycle (AI-DLC). AWS DevOps and Developer Productivity Blog, 2026. Link.[AWS - re:Invent 2025 DVT214]Mishra A and Raja SP. Introducing AI-Driven Development Lifecycle (AI-DLC). AWS re:Invent 2025, session DVT214. Recording.[3P]ThoughtWorks AI/works. https://www.thoughtworks.com/ai/works.[3P - ThoughtWorks 2024]How much faster can coding assistants really make software delivery? Thoughtworks Insights, 2024. Link.
APS context
[3P]GovAI (Department of Finance). https://www.govai.gov.au/.[3P]GovAI AIDE. https://www.govai.gov.au/aide.[3P]Norton Rose Fulbright. The Australian Public Service AI Plan 2025: A legal and commercial roadmap. 2025. Link.[3P]Policy for the responsible use of AI in government, Version 2.0. Digital Transformation Agency, effective 15 December 2025. Link. Policy PDF.[3P]Digital Service Standard v2.0. Digital Transformation Agency. Link.[3P]Introducing the APS AI Plan. Department of Finance, 12 November 2025. Link.
Theory / foundations
[3P]Poppendieck, M. and Poppendieck, T. Lean Software Development: An Agile Toolkit. Addison-Wesley, 2003.[3P]Forsgren, N., Humble, J. and Kim, G. Accelerate: The Science of Lean Software and DevOps. IT Revolution Press, 2018.
Author judgment
[AJ] Used throughout where analysis is the author's synthesis rather than a sourced claim. Examples: illustrative 10%-work-time math, APS extension pack sizing, role reconciliation, watch-outs.
Appendix D — Trial Implementation: Auto Search with AI-DLC and Superpowers
Subject
Auto Search is a semantic search feature for an analytics workbench. It fills a usability gap where users cannot find data items and indicators without knowing the exact domain-specific terms. Three design choices differentiate the approach:
- LLM-generated synthetic training corpus.
- Domain fine-tuning of an embedding model on that corpus, to capture domain nuance.
- ONNX export with native Java inference, sized to load completely into memory for in-process similarity search.
Comparison
Superpowers is an open-source skill framework for AI coding agents, structured as a library of opt-in skills: brainstorming, writing-plans, executing-plans, test-driven-development, systematic-debugging, requesting-code-review and verification-before-completion among them [3P]. Superpowers targets individual developers rather than delivery teams; the artefact set is flatter than AI-DLC's and there is no native concept of multi-role review or team handoff.
Auto Search was selected as the trial subject because it was the active build at the time this report was written, not because it was representative of APS delivery in general. Superpowers was selected as the comparison because it was in concurrent use during the trial, not because it is a like-for-like alternative to AI-DLC. See Limitations for the full set of caveats.
Process
- Started in Superpowers. The generated specification became the seed for AI-DLC Inception.
- Completed both Superpowers and AI-DLC workflows in parallel with minimal cross-feeding, apart from a manual specification update in AI-DLC to increase the training corpus from 30 to 350 items and add a rate limit when calling the Anthropic Haiku API. Both were learned from the Superpowers implementation.
- Reuse of Superpowers' generated
corpus.json, as AI-DLC did not execute the corpus generation instruction despite receiving it. - After 15 explicit review gates in AI-DLC with three Units still remaining, the author elected to autocomplete the remaining work with recommended options to avoid review fatigue and finish the trial.
Metrics
| # | Metric | AI-DLC | Superpowers |
|---|---|---|---|
| 1 | Total time | ~10h | ~4.5h |
| 2 | Explicit approvals | ~20 (15 Mob Approval gates · 3 plan-level · 2 extension opt-in); all ceased after autonomous-mode directive | ≥7 (detected during post-implementation review) |
| 3 | Clarification rounds / questions | 12 rounds · ~78 questions (pre-autonomous); 0 post-autonomous | 2 documented; more likely unrecorded |
| 4 | Working documents | 75 (inception 18 · construction design/summaries 50 · build-and-test 5 · spec 1 · README 1) | 4 (implementation plan · design spec · repo README · project README) |
| 5 | Lines in working documents | 9,253 (inception 3,427 · construction 4,872 · audit+state 417 · spec 325 · README 212) | 2,954 (plan 2,440 · spec 325 · repo README 176 · project README 13) |
| 6 | Code artefacts (count) | 58 source files (Python 11 · Java 15 · Vue/JS 10 · Terraform 14 · config 8); 14 test files | 32 code files (Java 8 · frontend 7 · Python 11 · config/data-schema 6); 8 project data artefacts |
| 7 | Code artefacts (LOC) | Code 2,756 · tests 901 · total 3,657; data: corpus 2.7 MB · pairs 452 KB · model.onnx 86 MB ×2 | Code 1,539; data ~1,056 human-authored lines + 136,851 machine-generated embedding vector lines |
| 8 | Test cases / coverage | 58 cases (pytest ~39 · JUnit ~12 · Vitest ~7); coverage not measured | 73 total (unit/component 53 · eval queries 20); functional coverage ~70–75% estimated |
| 9 | Code quality / tech debt / security | Claude assessment: Moderate | Claude assessment: High |
| 10 | Git commits | 7 | 35 |
| 11 | Commit velocity | 0.70 commits/hr; clusters at stage-gate boundaries | ~8 commits/hr |
| 12 | Fix-to-feature ratio | ~17% | 23% |
| 13 | Docs-to-code ratio | 2.53:1 | 1.9:1 |
| 14 | Plan task completion | 87/148 = 59% | 19/19 = 100% |
| 15 | Model lift (Recall@1) | Fine-tuned tied baseline (0.50, 0.0 Δ vs all-MiniLM); FAIL | 0.75 → 0.85 (+13.3%) |
| 16 | Model lift (MRR@5) | Curated: 0.533 (0.0 Δ vs all-MiniLM); synthetic: 0.789 vs bge-small 0.819 (−0.030); FAIL | 0.81 → 0.91 (+12.3%) |
Top five differences
- Total active time (2.2× heavier). AI-DLC required ~10h of active effort versus ~4.5h for Superpowers. The gap likely reflects AI-DLC's greater documentation and review focus.
- Working document volume (18.75× more). 75 documents and 9,253 lines versus 4 documents and 2,954 lines. This is a philosophy difference, not a productivity failure. AI-DLC optimises for team handoff, audit completeness, and role separation; Superpowers optimises for solo throughput. The overhead is a feature at team scale; it is a significant cost for a single practitioner working alone.
- Human interaction load (39× more questions). AI-DLC generated 12 clarification rounds with ~78 questions before autonomous mode was activated; Superpowers raised 2 documented decision points. This is the clearest expression of the target-audience mismatch: AI-DLC simulates a multi-role team conversation that a solo practitioner must play alone, fielding questions directed at a PM, BA, architect, and tech lead simultaneously.
- Plan task completion (59% vs 100%). The autonomous-mode directive resolved the interaction load but broke the completion signal. AI-DLC's deeper task decomposition (148 versus 19) created more surface area for untracked work, and once human oversight was removed, the audit trail stopped reflecting actual progress.
- Model fine-tuning outcome (FAIL vs +13% lift). AI-DLC's fine-tuned model failed to improve on the best baseline on both test sets; Superpowers produced a +13.3% Recall@1 and +12.3% MRR@5 improvement. The proximate cause is a confound: AI-DLC skipped the synthetic corpus generation step despite an explicit instruction. This surfaces a real instruction-adherence gap that would carry practical consequences in a production delivery.
Observations
| Dimension | AI-DLC | Superpowers |
|---|---|---|
| Target audience | Delivery teams. Explicit roles for PM, BA, data scientist, lead developer to participate or review. | Solo developers. |
| Methodology structure | Structured, industry-standard use cases (DDD at the core). | Lightweight: specification plus implementation plan as the two primary artefacts. |
| Requirements depth | Deeper probe of requirements and design options, especially UI/UX. | Elaboration and review enforced, but at shallower depth. |
| Cross-session consistency | Caught an inconsistency where a confidence cutoff was specified as 0.4 early and referenced as 0.3 later. | Did not reliably catch cross-session inconsistencies; manual prompting required. |
| Visual design support | Not a first-class output. | Presents UI design options visually for refinement and review. |
| Review burden | High. Review fatigue set in at ~15 gates with more to go. | Lower; two primary artefacts to review. |
| Instruction adherence | Skipped the 350-item synthetic corpus generation and the .env pattern for API keys despite explicit prompts. | Generated the synthetic corpus as instructed. |
| Git integration | No automatic commit on task completion. | Auto-commits to Git after task completion. |
| Model optimisation | No automated quantisation. | Quantised the custom model from 86 MB to 22 MB automatically. |
| Cost and quality guardrails | Explicit LLM API cost and code quality guardrails. | Not explicit. |
| Audit trail | Comprehensive logging of interactions and decisions. | Minimal. |
| Team work distribution | Units decompose to sizes that can be distributed across a team. | Task-level decomposition does not map to team work distribution. |
| APS standards awareness | Not native; requires extensions. | Not native; requires heavy customisation. |
Takeaway [AJ]: AI-DLC's richer role model and cross-session consistency checking pay off on complex, multi-party features; the cost is review load. Superpowers' automation touches (auto-commit, auto-quantise) were the pleasant surprises and reflect its solo-developer origin. Neither tool ships with APS standards awareness; both need extension work before production use in a regulated program.
Change Log
- 2026-04-23: Initial draft. Part 1 (IT executive brief), Part 2 (delivery team guide), Appendices A–C.
- 2026-04-24: Author review and structural trim. Retitled paper. Removed Roadmap and FAQ sections. Reviewed citations and claims. Paper date advanced to 2026-04-24.
- 2026-04-24: Added Limitations section disclosing scope and sample boundaries. Added Appendix D with Auto Search trial process and consolidated AI-DLC vs Superpowers observation table.
- 2026-04-24: Added quantitative metrics table and top five differences commentary to Appendix D.
- 2026-04-27: Final review. Added Superpowers comparison block in Appendix D and split trial-rationale sentence to handle Auto Search and Superpowers separately. Added URLs for DTA AI Policy v2.0, Digital Service Standard v2.0 and APS AI Plan 2025 in Appendix C.
End of paper.